
Machine learning is increasingly moving from the cloud to the edge – running directly on mobile and IoT devices. This “edge-first” approach to ML emphasizes deploying models on-device by default, which offers critical benefits. By processing data locally, edge ML enhances privacy and security (sensitive data never leaves the device) and delivers real-time responsiveness without network delays. It also enables offline functionality for apps that must work without internet connectivity. In short, edge-first ML can democratize AI – bringing sophisticated language understanding to smartphones, wearables, and embedded systems – but it comes with significant technical challenges. Deploying large language models (LLMs) on small devices requires rethinking architectures and optimizations to overcome severe resource constraints.
Constraints of on-device language models
Edge devices operate under strict resource constraints. Unlike cloud servers, a phone or microcontroller has limited memory, processing power, and battery capacity. For example, state-of-the-art LLMs can require hundreds of gigabytes of memory (GPT-4 is an extreme case), whereas a typical mobile device might have only 1-8 GB of RAM. Edge CPUs/NPUs also provide only a fraction of the compute throughput of datacenter GPUs. These limitations make it infeasible to run large models without significant optimization. Moreover, edge deployments are constrained by power and latency: battery-powered devices demand energy-efficient inference, and many applications (e.g. voice assistants, AR translation) need response times under ~100 ms. If a model consumes too much power or time, it can drain batteries or produce lag, undermining the user experience. In summary, the key challenges for on-device LLMs include:
- Memory footprint: Models must fit in limited RAM/storage without overflow.
- Compute limitations: Inference has to run on low-clock CPUs or specialized NPUs with limited throughput.
- Energy efficiency: Algorithms should minimize power draw to preserve battery life.
- Latency sensitivity: Optimizations are needed to meet real-time latency requirements (often <100ms).
To meet these constraints, developers employ a range of architectural patterns and system strategies described below.
Model compression techniques
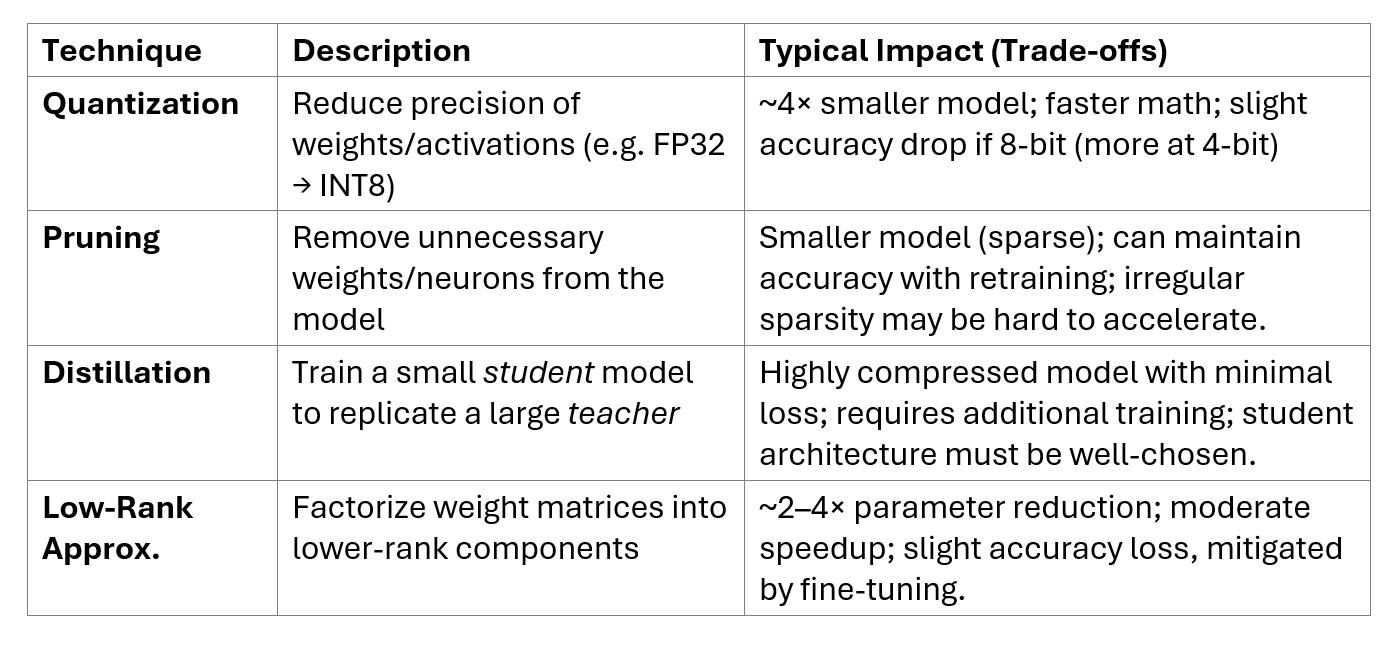
The first line of defense in building tiny language models is model compression – reducing model size and complexity while preserving accuracy. Through clever optimizations, a large network can be transformed into a smaller, faster one that’s feasible for edge deployment. Major compression techniques include:
- Quantization: Lowering the numeric precision of model weights and operations. For instance, converting 32-bit floating point weights to 8-bit integers instantly cuts model size by 4× and speeds up math operations. More aggressive schemes use 4-bit or even 1-bit weights. Quantization can introduce some accuracy loss due to reduced precision, but often the impact is small if done carefully (e.g. with quantization-aware training). It has emerged as a key technique for efficient LLM inference on the edge, drastically shrinking memory and compute needs.
- Pruning: Removing redundant or less-important model parameters (e.g. weights or even entire neurons) to sparsify the network. Pruning can eliminate 50–90% of weights that contribute little to final predictions. The pruned model is smaller and faster, though usually some fine-tuning is required to recover lost accuracy. Structured pruning (dropping whole channels or attention heads) often yields more hardware-efficient models than unstructured weight pruning.
- Distillation: Training a compact student model to mimic the outputs of a larger teacher model. Knowledge distillation transfers the “knowledge” (learned behaviors) from a big LLM into a smaller one. This often achieves excellent accuracy relative to the size. A notable example is DistilBERT, a distilled version of BERT that retains 97% of BERT’s performance while being 40% smaller and 60% faster. Distilled models effectively serve as tiny LMs tailored for edge use-cases.
- Low-rank factorization: Decomposing large weight matrices (such as Transformer attention or feed-forward layers) into lower-rank approximations. By representing the weight matrix as the product of two smaller matrices, we reduce parameter count. This technique exploits linear algebra structure to compress models with moderate accuracy impact, and can be combined with the above methods.
By combining these techniques (and sometimes using all of them together), engineers can shrink massive LLMs down to a size suitable for mobile or IoT devices. For example, the Meta LLaMA 7B model has been quantized to 4-bit and distilled into even smaller variants to run on phones. Model compression is an active research area, with new methods (like neural architecture search for efficient models, parameter sharing schemes, etc.) continually pushing the envelope.
Modular and adaptive inference
Beyond compressing the model itself, how the model is executed can be optimized through modular and adaptive inference strategies. The idea is to avoid doing unnecessary work during inference and tailor computation to the input or context, thereby saving time and energy on-device.
- Early exit mechanisms: Not every input requires the full depth of an LLM to get a confident result. Early-exit architectures introduce intermediate exit points in the model (for example, after certain Transformer layers) where the model can output a result if it is confident enough. If a simple query can be answered after 6 layers, the remaining layers are skipped, cutting computation. This dynamic depth adjustment ensures the device only expends maximal compute for hard examples, while easy inputs are handled quickly.
- Input chunking (Streamable inference): For tasks like long text generation or transcription, the model’s input can be processed in smaller chunks rather than all at once. By splitting a long sequence into segments and processing incrementally (possibly with a rolling context window), the peak memory usage stays lower, enabling tiny models to handle longer inputs than otherwise possible. Chunking also reduces latency by outputting partial results progressively instead of waiting for full completion. Many on-device speech recognizers and translators use streamable models that work chunk-by-chunk.
- Conditional computation and mixture-of-experts: An advanced pattern is to activate only relevant parts of the model for a given input. For instance, a mixture-of-experts (MoE) model may have multiple sub-networks (“experts”) but route each input through only one or few of them. This way, the effective model size per inference is small even if the overall model has large capacity. Similarly, techniques like dynamic width (adjusting how many neurons or attention heads are used based on input complexity) allow the model to conserve computation on simpler tasks. These approaches treat the model as modular pieces that can be turned on/off as needed, rather than a monolithic block that always runs fully.
- Adaptive runtime decisions: The system can also adjust when and how to run the model based on runtime conditions. For example, if the device is overheating or battery is low, the inference engine might dynamically switch to a lower-power mode – using a smaller model or throttling the frequency. Conversely, when plugged into power, it could afford to use a larger model if available. This runtime adaptivity extends to network conditions: if the device has a fast internet connection, it might offload a complex request to a cloud LLM, but fall back to the on-device model in offline or poor connectivity scenarios. Such adaptive scheduling ensures optimal performance while respecting device constraints in real time.
Hardware Acceleration on the Edge
To squeeze out maximum performance per watt, on-device ML leverages specialized hardware accelerators. Modern mobile SoCs often include NPUs (Neural Processing Units) or DSPs designed for efficient neural network inference. These chips can run matrix multiplications and other deep learning operations far more efficiently than general-purpose CPUs. By using frameworks that target these accelerators (e.g. via Android Neural Networks API or Apple’s Core ML), developers can achieve significant speed-ups and energy savings. For instance, Qualcomm’s Hexagon DSP or Apple’s Neural Engine can execute quantized neural network operations with high throughput, enabling real-time language processing on phones. Hardware accelerators are especially powerful when models are quantized, since many NPUs have optimized integer math units.
In addition to mobile NPUs, there’s a broader ecosystem of edge AI hardware: from NVIDIA Jetson devices with small GPUs, to Google’s Coral and Edge TPU devices, FPGAs for custom acceleration, and even tiny microcontroller-class accelerators. Each comes with its own software stack. Deploying a model efficiently means targeting the model to the specific hardware. Specialized kernels and libraries (e.g. using vectorized SIMD instructions on CPU, or using GPU Tensor Cores) further improve throughput. A core part of “edge-first” design is being hardware-aware – choosing model architectures and optimizations that map well to the device’s capabilities (e.g. favoring operations that an NPU can execute in silicon). As new AI chips emerge (NPUs, TPUs, ASICs designed for neural nets), on-device LLMs will continue to gain performance.
Dynamic Offloading (Edge-Cloud Hybrid Systems)
Sometimes the best solution combines both edge and cloud. Dynamic offloading techniques allow a model to split execution between the device and cloud servers, or to switch over entirely to a cloud model for especially heavy tasks. This hybrid approach seeks to get the best of both worlds: the low latency and privacy of on-device inference, plus the raw power of the cloud when needed. For example, a mobile assistant might normally use a small on-device language model for simple queries, but if the query is very complex (or the user’s device is currently resource-starved), it could securely send the request to a cloud API for a larger model to handle. Some systems even partition a single model’s layers between device and cloud – running the early layers on-device and streaming intermediate results to the cloud to finish the computation (and vice-versa).
The decision to offload can be made at runtime based on network availability, user preferences, or real-time inference benchmarks. Research prototypes like Neurosurgeon have explored dynamically deciding where to execute different parts of a DNN to minimize latency under given bandwidth conditions. More recently, hybrid inference for LLMs has been proposed where a small LM (SLM) on the edge handles most tokens, but occasionally consults a large LM in the cloud for more complex reasoning. In practice, edge-cloud collaboration requires careful design to ensure secure data transfer (maintaining user privacy) and fast switching without introducing too much overhead. When done right, however, edge-first doesn’t have to mean edge-only – intelligent offloading can significantly extend the capabilities of tiny models by tapping into cloud resources when appropriate.
System-level strategies: Adaptivity and security
Building a robust on-device ML system isn’t just about the model architecture – it also involves runtime system strategies and safeguards:
- Resource-aware adaptivity: The deployment runtime should continuously adapt to the device’s state. This can include thermal throttling (e.g. if the phone gets hot, run the model on fewer cores or slower), battery-aware mode (trading off accuracy for lower power when battery is low), and CPU/GPU scheduling to avoid impacting foreground app responsiveness. Adaptive load-shedding strategies might skip non-critical model invocations if the device is under heavy load. The goal is a graceful degradation – ensuring the AI features remain usable under constraint, possibly with reduced fidelity, rather than failing outright.
- Secure and private deployment: When ML models live on user devices, new security considerations arise. Models should be protected against extraction or tampering – techniques like model encryption, obfuscation, or running in secure enclaves can help prevent attackers from stealing the model or inserting backdoors. Secure update mechanisms are essential so that model files can be updated or patched without risk of compromise. Additionally, keeping data on-device by design improves privacy (no sensitive text or audio needs to leave the device), but developers should still enforce data handling policies and guard against leaks (for example, scrub any personally identifiable info if partial offloading to cloud is used). Compliance with regulations (GDPR, HIPAA, etc.) must be considered when edge devices handle user data. In summary, edge ML systems require a holistic security mindset – protecting both the model IP and the user’s data.
Frameworks, Tools, and Benchmarks
A number of frameworks and tools are available to support edge LLM development:
- TensorFlow Lite: Google’s lightweight ML runtime for mobile/embedded devices, which provides conversion tools to compress models and hardware acceleration (via NNAPI, GPU, and other delegates). TFLite is often used to deploy quantized models on Android phones and microcontrollers (TensorFlow Lite for Microcontrollers for the tiniest devices).
- PyTorch Mobile: A mobile-friendly version of PyTorch that can package trained models for Android and iOS apps. It supports quantization and offers integration with device-specific libraries. PyTorch also has TorchScript and Accelerated PT backends to optimize models for edge inference.
- ONNX Runtime: An open-source inference engine by Microsoft that supports the ONNX format across platforms. ONNX Runtime has special builds for mobile (Android, iOS) and can leverage hardware accelerators. It enables a deploy-once-run-anywhere approach, where you export a model to ONNX and run it on different devices with the same runtime.
- Apache TVM: An ML compiler framework that can auto-tune and compile models for optimal performance on a given hardware target. TVM can generate highly optimized code for CPUs, GPUs, NPUs, and even microcontrollers, often beating out-of-the-box framework performance.
- MLPerf Tiny: A benchmark suite from MLCommons targeting ultra-low-power ML systems. MLPerf Tiny defines standard tasks (e.g. keyword spotting, visual wake words) to objectively measure how well tiny models perform on microcontrollers and edge hardware. It’s geared for models under 100 kilobytes and power usage in the tens of milliwatts. The benchmark’s existence underscores the growing importance of TinyML – a community effort to push ML into even the smallest devices. MLPerf Tiny results can guide engineers in choosing the right hardware and techniques for edge deployments, and foster competition in efficient model design.
In addition to the above, there are many open-source tools and examples to learn from. Frameworks like TensorFlow Model Optimization Toolkit and PyTorch Quantization provide APIs for pruning and quantizing models. Projects like TinyML and EdgeML (by Microsoft) offer algorithm libraries for compressing models. Real-world applications, such as on-device translation in Google Translate and Apple’s on-device speech recognition, serve as case studies of what’s possible: Google reported using quantized RNN transducer models on Pixel phones for voice typing, and Apple’s Neural Engine runs transformer models for Siri entirely offline on-device. These illustrate how the pieces come together: a compressed model, running on specialized hardware, orchestrated by an adaptive runtime, yields a practical edge AI feature.
Real-time, private language AI on mobile and IoT
Edge-first machine learning is enabling a new generation of intelligent mobile apps and IoT devices that can understand language in real-time, privately and reliably. Achieving this requires overcoming strict constraints with clever architecture patterns: compressed models, modular inference, hardware acceleration, and sometimes cloud collaboration. Equally important are system-level techniques to adapt to device conditions and keep deployments secure. The field is rapidly evolving – for instance, efficient Transformers and novel quantization schemes are continually improving on-device LLM performance.
By leveraging the patterns discussed – quantization and pruning for slim models, early exits and dynamic offloading for efficient execution, NPUs and compilers for speed, and robust edge runtimes – ML engineers and mobile developers can bring language AI to the edge. The result is tiny yet capable language models that run right where users need them, unlocking responsive AI assistants, real-time translators, and more, all without relying on the cloud. Edge-first ML is poised to fundamentally change how we build interactive intelligent applications, making them more personal, responsive, and privacy-preserving by design.
Have a LLM setup/fine-tuning use-case you are having difficulties with? Lodge an email to info@acmeai.tech and our team will help you out.